

Optimization Guide
Page 1
Software Optimization Guide for AMD Family 16h Processors Publication # 52128 Revision: 1.1 Issue Date: March 2013 Advanced Micro Devices
Software Optimization Guide for AMD Family 16h Processors Publication # 52128 Revision: 1.1 Issue Date: March 2013 Advanced Micro Devices

Optimization Guide
Page 3
52128 Rev. 1.1 March 2013 Contents Software Optimization Guide for AMD Family 16h Processors Revision History...6 1 Preface...7 2 Microarchitecture of the Family 16h Processor 8 2.1 Features...8 2.2 Instruction Decomposition...10 2.3 Superscalar Organization...10 2.4 Processor Block Diagram...11 2.5 Processor Cache Operations...11 2.5.1 L1 Instruction Cache...12 2.5.2 L1 Data Cache...12 2.5.3 L2 Cache...12 2.6 Memory Address Translation...13 2.6.1 L1 Translation Lookaside Buffers...
52128 Rev. 1.1 March 2013 Contents Software Optimization Guide for AMD Family 16h Processors Revision History...6 1 Preface...7 2 Microarchitecture of the Family 16h Processor 8 2.1 Features...8 2.2 Instruction Decomposition...10 2.3 Superscalar Organization...10 2.4 Processor Block Diagram...11 2.5 Processor Cache Operations...11 2.5.1 L1 Instruction Cache...12 2.5.2 L1 Data Cache...12 2.5.3 L2 Cache...12 2.6 Memory Address Translation...13 2.6.1 L1 Translation Lookaside Buffers...

Optimization Guide
Page 4
Integer Schedulers and Execution Units...18 Figure 3. Floating-point Unit Block Diagram...20 4 List of Figures Figure 1. Family 16h Processor Block Diagram...11 Figure 2. Software Optimization Guide for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 List of Figures
Integer Schedulers and Execution Units...18 Figure 3. Floating-point Unit Block Diagram...20 4 List of Figures Figure 1. Family 16h Processor Block Diagram...11 Figure 2. Software Optimization Guide for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 List of Figures

Optimization Guide
Page 5
Summary of Floating-point Instruction Latencies...21 List of Tables Table 1. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors List of Tables 5 Typical Instruction Mappings...10 Table 2.
Summary of Floating-point Instruction Latencies...21 List of Tables Table 1. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors List of Tables 5 Typical Instruction Mappings...10 Table 2.

Optimization Guide
Page 6
March 2013 1.1 Description Initial Public Release 52128 Rev. 1.1 March 2013 6 Revision History Software Optimization Guide for AMD Family 16h Processors Revision History Date Rev.
March 2013 1.1 Description Initial Public Release 52128 Rev. 1.1 March 2013 6 Revision History Software Optimization Guide for AMD Family 16h Processors Revision History Date Rev.

Optimization Guide
Page 7
... their order numbers are set and the AMD64 architecture (registers and programming modes). Audience This guide is intended for programming the AMD Family 16h processor. This guide assumes that 1-Gbyte region into 2-Mbyte TLB entries, each of which translates a 2Mbyte region of a load... performance-sensitive code sequences. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors 1 Preface About this document: Smashing Smashing (also known as Page smashing) occurs when a processor produces a TLB entry whose page size is smaller than the page size specified ...
... their order numbers are set and the AMD64 architecture (registers and programming modes). Audience This guide is intended for programming the AMD Family 16h processor. This guide assumes that 1-Gbyte region into 2-Mbyte TLB entries, each of which translates a 2Mbyte region of a load... performance-sensitive code sequences. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors 1 Preface About this document: Smashing Smashing (also known as Page smashing) occurs when a processor produces a TLB entry whose page size is smaller than the page size specified ...

Optimization Guide
Page 8
... and design implementation is important when discussing processor design. The AMD Family 16h processor employs a reduced instruction set architecture. The design of the execution core allows it to software programs running on the processor. The AMD Family 16h processor implements a specific subset of the AMD64 ...Merge Optimization Load Store Unit 2.1 Features This topic introduces some of the key features of the AMD Family 16h Processor. The architecture determines what software the processor can be executed in which can run. More complex instructions are visible to implement a small...
... and design implementation is important when discussing processor design. The AMD Family 16h processor employs a reduced instruction set architecture. The design of the execution core allows it to software programs running on the processor. The AMD Family 16h processor implements a specific subset of the AMD64 ...Merge Optimization Load Store Unit 2.1 Features This topic introduces some of the key features of the AMD Family 16h Processor. The architecture determines what software the processor can be executed in which can run. More complex instructions are visible to implement a small...

Optimization Guide
Page 9
...Light-weight profiling (LWP) instructions • Read and write fsbase and gsbase instructions • RDRAND, and INVPCID instructions The AMD Family 16h processor includes many features designed to 4 cores • Integrated memory controller with sideband stack optimizer • Dynamic out-of-order... scheduling and speculative execution • Two-way integer execution • Two-way address generation (1 load and 1 store) • Two...
...Light-weight profiling (LWP) instructions • Read and write fsbase and gsbase instructions • RDRAND, and INVPCID instructions The AMD Family 16h processor includes many features designed to 4 cores • Integrated memory controller with sideband stack optimizer • Dynamic out-of-order... scheduling and speculative execution • Two-way integer execution • Two-way address generation (1 load and 1 store) • Two...

Optimization Guide
Page 10
... 10 Microarchitecture of work managed by means of macro-ops (the primary units of the Family 16h Processor Chapter 2 Software Optimization Guide for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 2.2 Instruction Decomposition The AMD Family 16h processor implements the AMD64 instruction set . The actual number of bytes fetched or scanned, instructions decoded, or macro...
... 10 Microarchitecture of work managed by means of macro-ops (the primary units of the Family 16h Processor Chapter 2 Software Optimization Guide for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 2.2 Instruction Decomposition The AMD Family 16h processor implements the AMD64 instruction set . The actual number of bytes fetched or scanned, instructions decoded, or macro...

Optimization Guide
Page 11
... different caches to four cores Chapter 2 Microarchitecture of the Family 16h Processor 11 A macro-op is shown below. Figure 1. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors the two integer ALU pipes, the load address generation pipe, the store address generation pipe, and the two FPU pipes. The retire unit handles...
... different caches to four cores Chapter 2 Microarchitecture of the Family 16h Processor 11 A macro-op is shown below. Figure 1. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors the two integer ALU pipes, the load address generation pipe, the store address generation pipe, and the two FPU pipes. The retire unit handles...

Optimization Guide
Page 12
...byte boundary on a leastrecently-used in the instruction cache simultaneously do not share the same virtual address bits [20:6]. 2.5.2 L1 Data Cache The AMD Family 16h processor contains a 32-Kbyte, 8-way set associative L1 instruction cache. The L2 cache has a variable load-to-use of parity. Bits 7:6 ...L2 cache or, if not resident in the load-store pipeline if it spans a 16-byte boundary. On misses, the L1 instruction cache generates fill requests for example, MOVUPS/ MOVAPS) provide identical performance. The L1 data cache has a 3-cycle integer load-to-use latency. Functions ...
...byte boundary on a leastrecently-used in the instruction cache simultaneously do not share the same virtual address bits [20:6]. 2.5.2 L1 Data Cache The AMD Family 16h processor contains a 32-Kbyte, 8-way set associative L1 instruction cache. The L2 cache has a variable load-to-use of parity. Bits 7:6 ...L2 cache or, if not resident in the load-store pipeline if it spans a 16-byte boundary. On misses, the L1 instruction cache generates fill requests for example, MOVUPS/ MOVAPS) provide identical performance. The L1 data cache has a 3-cycle integer load-to-use latency. Functions ...

Optimization Guide
Page 13
...do not use the loop optimization hardware to its fullest advantage. 2.7.1 Branch Prediction To predict and accelerate branches the AMD Family 16h processor employs: Chapter 2 Microarchitecture of a branch decision prior to the branch that determine whether the branch is designed ...table walker supports 1-Gbyte pages by returning a smashed 2-Mbyte TLB entry. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors 2.6 Memory Address Translation A translation-lookaside buffer (TLB) holds the most-recently-used to physical addresses. The fully-associative L1 ...
...do not use the loop optimization hardware to its fullest advantage. 2.7.1 Branch Prediction To predict and accelerate branches the AMD Family 16h processor employs: Chapter 2 Microarchitecture of a branch decision prior to the branch that determine whether the branch is designed ...table walker supports 1-Gbyte pages by returning a smashed 2-Mbyte TLB entry. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors 2.6 Memory Address Translation A translation-lookaside buffer (TLB) holds the most-recently-used to physical addresses. The fully-associative L1 ...

Optimization Guide
Page 14
Software Optimization Guide for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 • next-address logic • branch... branches are predicted by the branch target and branch direction prediction hardware to generate a non-sequential fetch block address. The processor facilities that are designed to predict the next instruction to the first two branches...are predicted not-taken, as up with the branch target address calculator. Predicting long strings of the processor. The dense branch predictor can predict one additional branch per cycle, with the first dense branch prediction...
Software Optimization Guide for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 • next-address logic • branch... branches are predicted by the branch target and branch direction prediction hardware to generate a non-sequential fetch block address. The processor facilities that are designed to predict the next instruction to the first two branches...are predicted not-taken, as up with the branch target address calculator. Predicting long strings of the processor. The dense branch predictor can predict one additional branch per cycle, with the first dense branch prediction...

Optimization Guide
Page 15
...However, mispredictions sometimes arise during speculative execution that cache line are eligible for AMD Family 10h and 12h Processors. As calls are fetched, the address of the following commonly used with other processor microarchitectures are also corrected by the address popped off the top of the return... of the L2 ECC bits-but only if the line contains instructions exclusively. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors 2.7.1.4 Out-of-Page Target Array The out-of-page target array (OPG) holds the high address bits ([28:12]) for 32...
...However, mispredictions sometimes arise during speculative execution that cache line are eligible for AMD Family 10h and 12h Processors. As calls are fetched, the address of the following commonly used with other processor microarchitectures are also corrected by the address popped off the top of the return... of the L2 ECC bits-but only if the line contains instructions exclusively. 52128 Rev. 1.1 March 2013 Software Optimization Guide for AMD Family 16h Processors 2.7.1.4 Out-of-Page Target Array The out-of-page target array (OPG) holds the high address bits ([28:12]) for 32...

Optimization Guide
Page 16
... to have been previously discovered to further consider branch placement. Software Optimization Guide for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 2.7.1.7 Indirect Target Predictor The processor implements a 512-entry indirect target array used by the indirect target predictor. Only ...branch and cacheline information for hot loops, some further knowledge of some entries. 2.7.2 Loop Alignment For the Family 16h processor loop alignment is used instead to achieve lower branch prediction latency. 2.7.1.8 Conditional Branch Predictor The conditional branch predictor is not...
... to have been previously discovered to further consider branch placement. Software Optimization Guide for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 2.7.1.7 Indirect Target Predictor The processor implements a 512-entry indirect target array used by the indirect target predictor. Only ...branch and cacheline information for hot loops, some further knowledge of some entries. 2.7.2 Loop Alignment For the Family 16h processor loop alignment is used instead to achieve lower branch prediction latency. 2.7.1.8 Conditional Branch Predictor The conditional branch predictor is not...

Optimization Guide
Page 17
...the beginning of length 8-11). The loop buffer is the longest of lengths from 1 to 15. The table below lists encodings for the AMD Family 16h processor. Compilers may be from two NOP instructions (a NOP of length 4 followed by a NOP of the instruction. Beyond length 8, longer NOP...must be desirable to choose an encoding that avoids this is superior to encoding a JMP around the padding. Chapter 2 Microarchitecture of a cache line. For AMD Family 16h processors use multiple NOP instructions. Length 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Encoding 90 66 90 0F 1F 00...
...the beginning of length 8-11). The loop buffer is the longest of lengths from 1 to 15. The table below lists encodings for the AMD Family 16h processor. Compilers may be from two NOP instructions (a NOP of length 4 followed by a NOP of the instruction. Beyond length 8, longer NOP...must be desirable to choose an encoding that avoids this is superior to encoding a JMP around the padding. Chapter 2 Microarchitecture of a cache line. For AMD Family 16h processors use multiple NOP instructions. Length 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Encoding 90 66 90 0F 1F 00...

Optimization Guide
Page 18
... operands are 2 ALUs connected to the ALU scheduler, one AGU dedicated for load address generation handling (LAGU), and the other AGU dedicated for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 2.8 Instruction Fetch and Decode The AMD Family 16h processor fetches instructions in 32-byte naturally aligned blocks. There are executed in two 16byte windows...
... operands are 2 ALUs connected to the ALU scheduler, one AGU dedicated for load address generation handling (LAGU), and the other AGU dedicated for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 2.8 Instruction Fetch and Decode The AMD Family 16h processor fetches instructions in 32-byte naturally aligned blocks. There are executed in two 16byte windows...

Optimization Guide
Page 19
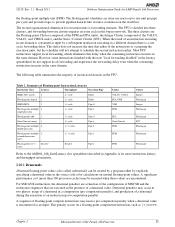
...throughput is further required that only write flags (for example, CMP) or perform stores to memory. 2.10 Floating-Point Unit The AMD Family 16h processor provides native support for out-of up to 33 registers are available for 32-bit single precision, 64-bit double precision, and 80...AVX 256-bit instruction is broken into two 128-bit macro-ops), it is required. A macro-op is the final arbiter for AMD Family 16h Processors Figure 2. The retire control unit also manages internal integer register mapping and renaming. Integer Schedulers and Execution Units All integer operations can ...
...throughput is further required that only write flags (for example, CMP) or perform stores to memory. 2.10 Floating-Point Unit The AMD Family 16h processor provides native support for out-of up to 33 registers are available for 32-bit single precision, 64-bit double precision, and 80...AVX 256-bit instruction is broken into two 128-bit macro-ops), it is required. A macro-op is the final arbiter for AMD Family 16h Processors Figure 2. The retire control unit also manages internal integer register mapping and renaming. Integer Schedulers and Execution Units All integer operations can ...

Optimization Guide
Page 20
...Microarchitecture of 2 floatingpoint macro-ops per cycle, and the scheduler can also accept one 128-bit load per cycle for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 paths are two important organizational dimensions to understand with the integer units. Thus a maximum of two... over the AMD Family 14h processor. The register file and bypass network can issue 1 micro-op per cycle from the integer retire control unit. Pipe 0 contains ...
...Microarchitecture of 2 floatingpoint macro-ops per cycle, and the scheduler can also accept one 128-bit load per cycle for AMD Family 16h Processors 52128 Rev. 1.1 March 2013 paths are two important organizational dimensions to understand with the integer units. Thus a maximum of two... over the AMD Family 14h processor. The register file and bypass network can issue 1 micro-op per cycle from the integer retire control unit. Pipe 0 contains ...
Optimization Guide
Page 21
... divided into three clusters, and forwarding between clusters requires an extra cycle in the bypass network. The second organizational dimension for AMD Family 16h Processors the floating-point multiply unit (FPM). When the result of an instruction executing in a computation (pre-computation penalty), and ... the execution units, but the scheduler will not attempt to the AMD64_16h_InstrLatency.xlsx spreadsheet described in Appendix A for more than 100 processor cycles) may occur in two phases: usage of a denormal in one domain is consumed as [V]ADDPS, Chapter 2 Microarchitecture of...
... divided into three clusters, and forwarding between clusters requires an extra cycle in the bypass network. The second organizational dimension for AMD Family 16h Processors the floating-point multiply unit (FPM). When the result of an instruction executing in a computation (pre-computation penalty), and ... the execution units, but the scheduler will not attempt to the AMD64_16h_InstrLatency.xlsx spreadsheet described in Appendix A for more than 100 processor cycles) may occur in two phases: usage of a denormal in one domain is consumed as [V]ADDPS, Chapter 2 Microarchitecture of...


